

분산락 어노테이션으로 재고의 중복 반영을 막고 보일러 코드를 제거한 경험 공유
분산락을 어노테이션으로 사용할 수 있도록 해보자
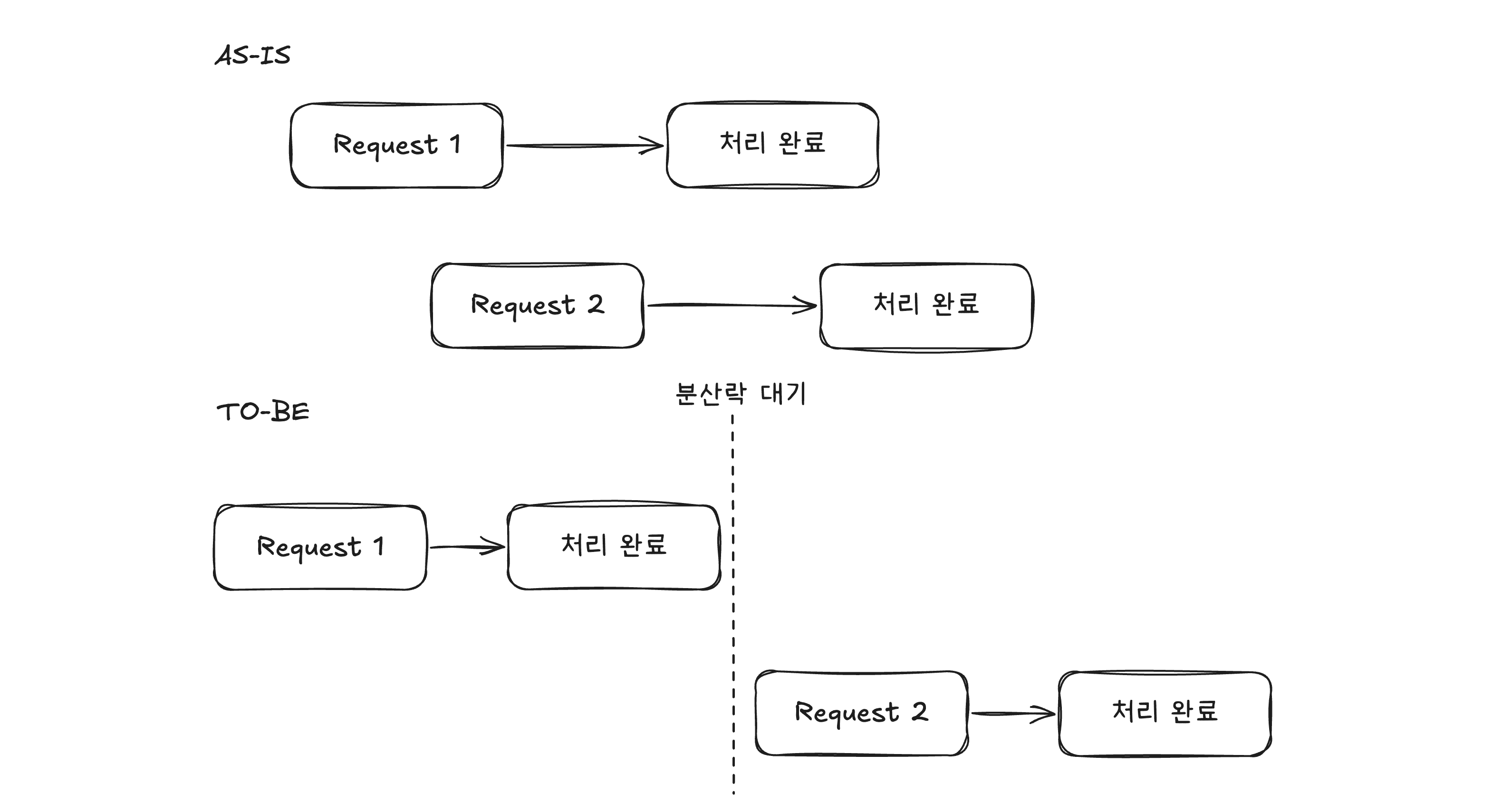
문제 상황
작업을 완료할 때에 어떤 재고를 몇개의 수량으로 완료를 했다고 보내는 기능이 있는데 해당 기능에서 중복 요청이 발생하는 문제가 있었습니다.
- 작업 완료 이벤트가 2번 씩 중복 요청됨 → 재고도 중복으로 반영됨
분석
비지니스 로직 상에서는 요청된 수량보다 완료된 수량을 더 많이 진행할 수 없도록 방어처리되고 있었지만 동시성 문제로 서로 다른 스레드에서 db에 반영되기 전에 병렬적으로 처리하다보니 중복적으로 반영하는 문제였습니다.
따라서 중복 요청에 대해서 방어할 수 있는 방법이 필요해진 상황입니다.
로컬 락을 건다
장점
- 구현이 단순- 트랜잭션 단위 내에서 강력한 제어 가능
단점
멀티 인스턴스 환경에서는 무력화
WAS 재시작 시 Lock 초기화
수평 확장 환경 부적합
분산 락을 건다
장점
다중 인스턴스 환경에서도 안전한 동기화 가능
타임아웃 설정으로 데드락 방지 가능
단점
구현 복잡도 높음
락 획득 실패 시 재시도 로직 필요
외부 장애에 민감 (Redis, ZK 장애 시 영향)
카프카를 통해서 비동기로 처리한다
장점
이벤트 기반 비동기 처리 가능
중복 방지 처리를 Kafka Consumer에서 집중 제어 가능
단점
중복 메시지 방지 로직을 애플리케이션에서 직접 구현해야 함
Kafka 자체의 At least once 특성으로 멱등성 보장 필요
DB를 이용한 낙관적 락을 건다
장점
DB 레벨에서 트랜잭션 충돌 방지 가능
재시도 전략과 함께 쓰면 신뢰성 높음
추가 인프라 필요 없음
단점
버전 충돌 시 로직 복잡도 증가
대량 이벤트 동시 처리 시 성능 병목 가능성
개발자가 충돌 처리 전략을 명확히 설계해야 함
개선 방안
결과적으로 제가 선택한 방법은 분산락을 사용하는 것 입니다

.
그 이유는 다음과 같습니다.
먼저 로컬 락을 사용하는 것은 MSA 환경에서 동시성을 해결해줄 수 있지 않기 때문에 제외
카프카를 이용한 방법의 경우 비지니스 기능이 부분 완료가 가능한 형태여서 단순 key로는 멱등성을 보장할 수 없어서 사용할 수 없다고 판단
낙관적락의 경우 작업의 영역과 재고의 영역은 도메인이 다르기 때문에 트랜잭션인 분리되어 있는데 현재 분산트랜잭션을 구현하기에는 너무 큰 비용이라고 판단
그 당시에 재고가 간혈적으로 틀어지고 있었기 때문에 따르게 대응하기 위해서 분산락을 사용하는 것으로 결정
제한된 시간과 자원 내에서 선택할 수 있는 방법은 분산락을 사용하는 것이였고 저는 이러한 분산락을 더 간편하게 사용할 수 있으면 좋겠다고 생각해서 다음과 같이 구현을 했습니다.
리서치를 해보니 컬리에서 저와 비슷한 고민을 했었고 분산락을 어노테이션으로 구현하는 것을 보고서 굉장히 좋은 방법이라고 생각을 해서 참고하게되었습니다.
Link : 풀필먼트 입고 서비스팀에서 분산락을 사용하는 방법 - Spring Redisson
- DistributedLock.java
@Retention(RetentionPolicy.RUNTIME)
public @interface DistributedLock {
String[] keys();
TimeUnit timeUnit() default TimeUnit.SECONDS;
long waitTime() default 0L;
long leaseTime() default 3L;
}
저는 락 사용을 좀 더 편하게 하기 위해서 커스텀을 했습니다. 먼저 key를 여러개 넣을 수 있도록 해서 사용의 편의성을 높였는데 각각의 key가 멀티로 락을 거는 것이 아니라 concat의 형태로 하나의 key를 만들어서 동작하도록 되어 있습니다.
- DistributedLockAop.java
@Slf4j
@Aspect
@Component
@RequiredArgsConstructor
public class DistributedLockAop {
private static final String REDISSON_LOCK_PREFIX = "LOCK:";
private final RedisLockExecutor redisLockExecutor;
@Around("@annotation(com.techtaka.argo.wms.job.common.util.lock.DistributedLock)")
public Object lock(final ProceedingJoinPoint joinPoint) throws Throwable {
MethodSignature signature = (MethodSignature) joinPoint.getSignature();
Method method = signature.getMethod();
DistributedLock distributedLock = method.getAnnotation(DistributedLock.class);
String totalKey = REDISSON_LOCK_PREFIX + Arrays.stream(distributedLock.keys())
.map(key -> getDynamicValueOrPlainValue(signature.getParameterNames(), joinPoint.getArgs(), key))
.collect(Collectors.joining("-"));
log.info("try lock : (key : {})", totalKey);
RedisLockExecutor.ExecutionResult<Object> result = redisLockExecutor.execute(
distributedLock.waitTime(),
distributedLock.leaseTime(),
distributedLock.timeUnit(),
totalKey,
joinPoint::proceed
);
if (result.hasException()) {
throw result.getException();
}
return result.getData();
}
private String getDynamicValueOrPlainValue(String[] parameterNames, Object[] args, String key) {
try {
return String.valueOf(CustomSpringELParser.getDynamicValue(parameterNames, args, key));
} catch (Exception exception) {
return key;
}
}
}
- CustomSpringELParser.java
public class CustomSpringELParser {
private CustomSpringELParser() {
}
public static Object getDynamicValue(String[] parameterNames, Object[] args, String key) {
ExpressionParser parser = new SpelExpressionParser();
StandardEvaluationContext context = new StandardEvaluationContext();
for (int i = 0; i < parameterNames.length; i++) {
context.setVariable(parameterNames[i], args[i]);
}
return parser.parseExpression(key).getValue(context, Object.class);
}
}
CustomSpringELParser 에서는 파라미터의 값을 동적으로 가지고 오기 위해서 문자열을 실제 파라미터 값으로 변환하는 작업을 처리합니다.
"#request.firstParam" -> request class에서 firstParam 필드 값
간단한 예시로는 이렇게 동작하도록 되어 있습니다.
결과
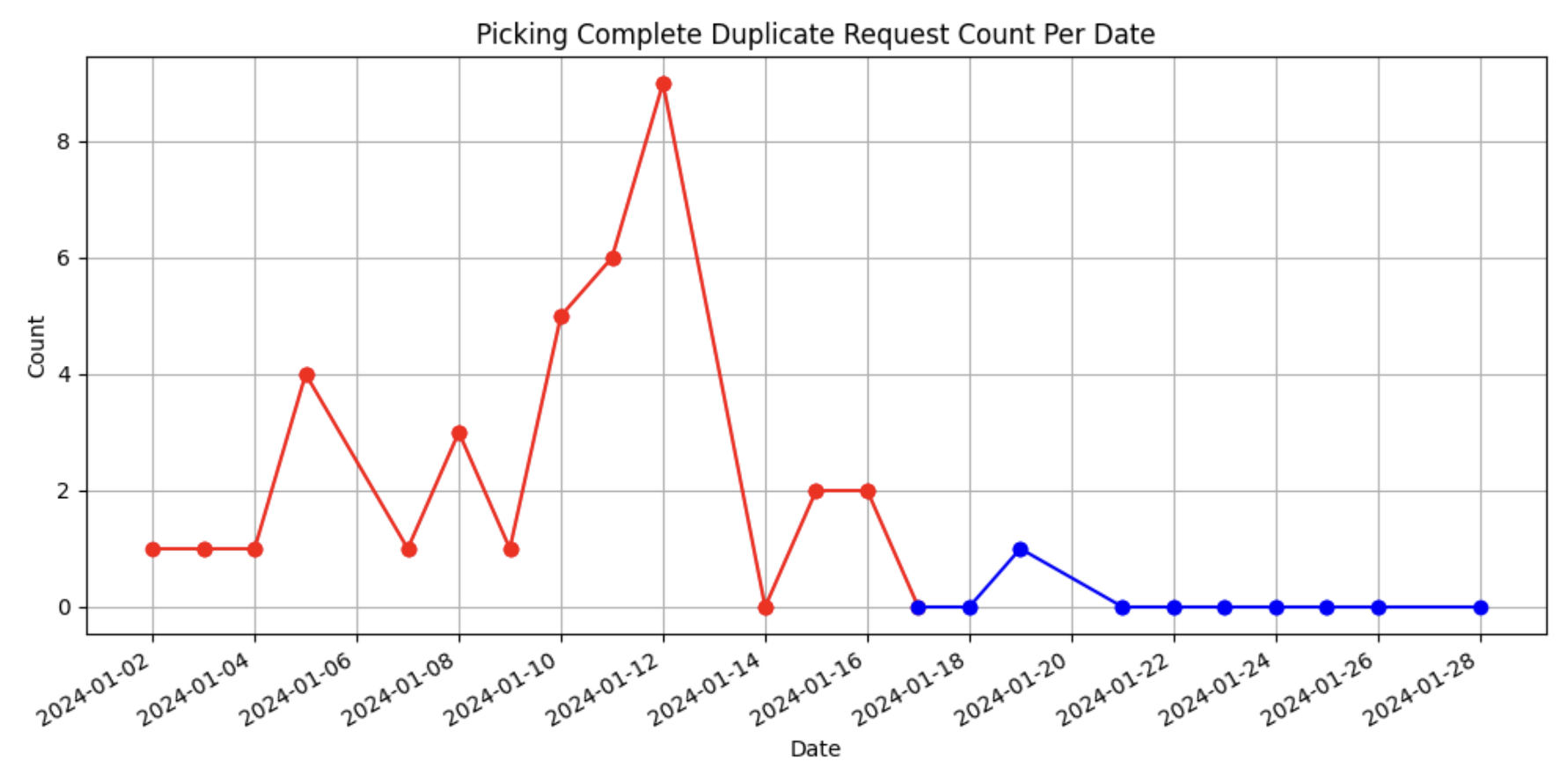
문제 해결 성과
• 기존 문제: 피킹 완료 이벤트가 간헐적으로 중복 요청되어 재고가 이중 반영되는 이슈가 발생
• 적용 조치: Redis 기반 분산 락(Distributed Lock) 적용
• 결과: 중복 요청이 완전히 사라짐 → 모니터링 그래프를 통해 명확하게 확인됨
구현 방식 개선을 통한 개발 생산성 향상
변경 전: 직접 Executor 방식변경 전
... 다른 로직
RedisLockExecutor.ExecutionResult<Object> result = redisLockExecutor.execute(
distributedLock.waitTime(),
distributedLock.leaseTime(),
distributedLock.timeUnit(),
totalKey,
joinPoint::proceed
);
if (result.hasException()) {
throw result.getException();
}
return result.getData();
구현 복잡도 높음
재사용 어려움
변경 후: 어노테이션 방식 간소화
@DistributedLock(keys = {"#someId"})
@PostMapping("/{someId}")
public SomeResponse somMethod(@PathVariable String someId) {
...
한 줄로 분산 락 적용 가능
개발자가 비즈니스 로직 구현에 집중 가능
코드 일관성과 유지보수성 개선
현재 WMS의 4개 이상의 도메인에서 분산락 어노테이션을 이용한 방법을 적극적으로 실사용 중
종합적으로 정리하면 다음과 같습니다
문제가 되었던 피킹 완료 중복 이벤트 완전 방지
개발 생산성 향상 → 4개 이상의 도메인에서 분산락 어노테이션을 이용한 방법을 적극적으로 실사용
고객 경험 개선 (정확한 재고 처리로 품질 신뢰성 확보)
느낀점
이번 기회를 통해서 락의 종류와 문제를 해결하기위해서는 락을 사용하지 않는 방법도 많이 고민을 했었습니다.
학교에서 이론으로 공부를 할 때에는 여러가지 시도를 해볼 수 있었지만 실제 현업에서는 이미 만들어진 거대한 성이 있어서 현실적인 제약 조건들이 많다는 것을 느꼈고 그 와중에서도 트레이드 오프를 생각해서 최선의 선택을 하는 것이 엔지니어로서의 역할이 아닌가 생각하게 되네요.