

약 27분 이상 걸리는 출고 지시 Api를 3초만에 동작하도록 개선한 경험 공유
사용자 경험을 높이기 위한 기능 최적화
1. 배경
회사 내부 시스템에서 제공하는 주문 처리 API가 실사용자에게 너무 긴 응답시간을 유발하고 있었습니다.
특히 약 300건의 주문을 처리하는 데 10~15분 이상이 소요되며, 이는 클라이언트의 **타임아웃(1분)**에 의해 실제로는 에러로 반환되고 있는 상황입니다.
문제의 핵심은 다음과 같습니다:
주문 처리 시간이 길어 클라이언트에서 먼저 커넥션이 끊어짐
상태머신 프레임워크가 bulk 처리 불가하고, 주문 1건씩 루프 처리
단일 API 호출이 파드의 CPU를 100%까지 소모하여 다른 요청도 영향을 받는 심각한 성능 문제가 발생
2. 가설
“상태머신 기반 처리를 API 요청 흐름 내에서 동기적으로 처리하기 때문에 병목이 발생하기에 로직을 Kafka 메시지를 통한 비동기 처리로 전환하면 성능 문제를 해결할 수 있다.”
3. 데이터 분석
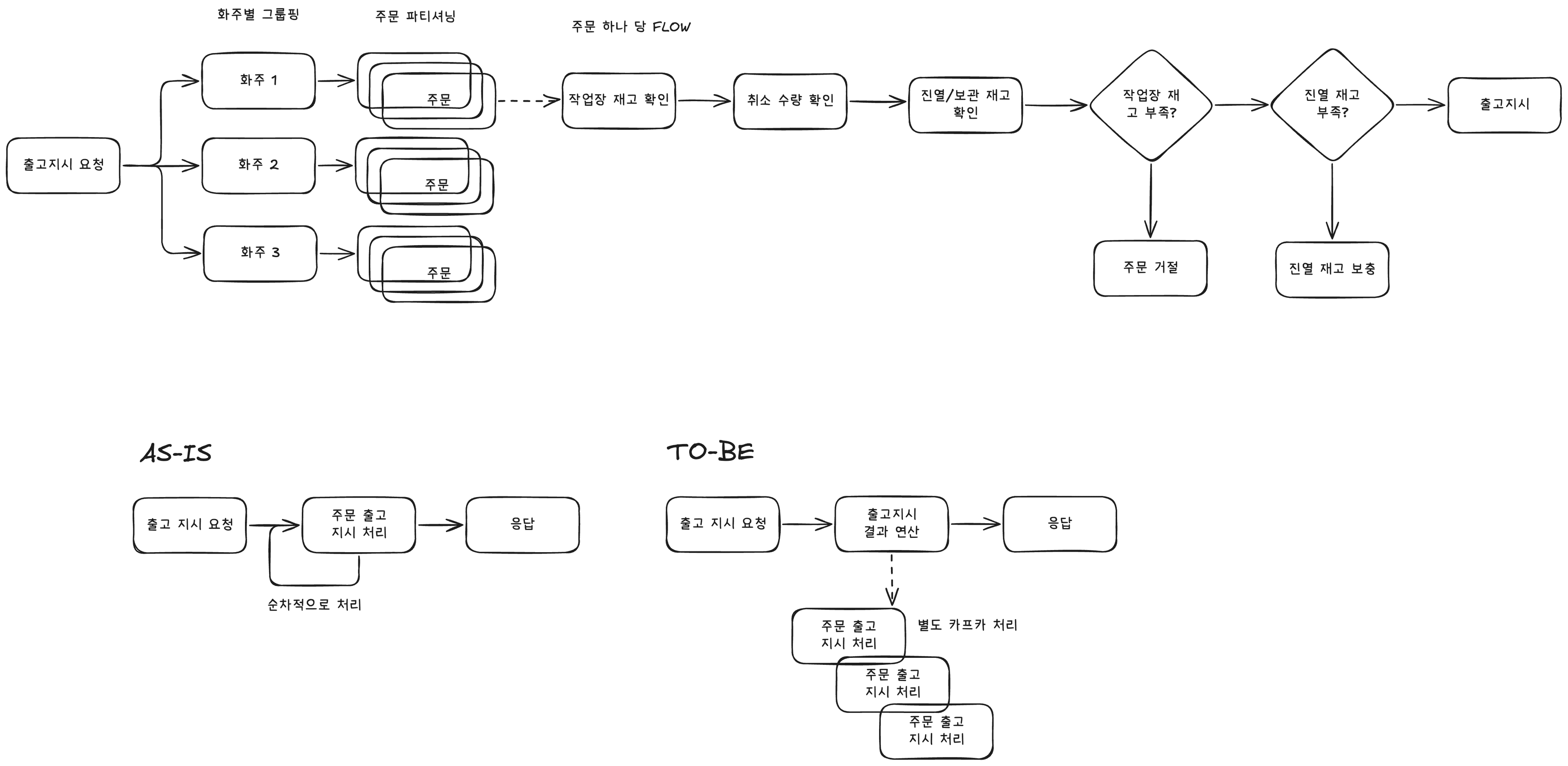
기존 구조 (AS-IS)
처리 방식 : 상태머신 호출을 API 흐름 내부에서 순차적으로 처리
처리 단위 : 주문 1건씩 순회 처리
병목 원인 : 상태머신 자체 처리 속도 + 연속 동기 호출 → 전체 API 응답 지연
리소스 사용 : 요청 처리 중 단일 POD의 CPU 사용률 100% 도달
결과 : 1분 이내 응답이 불가능 → API 실패
4. 결과
출고 지시 Flow Chart와 개선안

개선 방식 (TO-BE)
상태머신 트리거를 Kafka 메시지 발행 방식으로 전환
주문 수만큼 Kafka에 메시지를 전송하고, Consumer가 개별 처리
처리 흐름은 Lazy하게 진행되며, 처리 결과에 대해서 API는 빠르게 응답
성능 비교
성능 개선 수치를 확인하기 위해서 다음과 같이 테스트 및 확인을 했습니다.
DEV 환경
주문 수 : 300건
Kafka
partition : 1
concurrency : 2
API elapsed time : 약 28분 → 약 4초
실제 처리 시간 : 약 27분 → 약 10~15초
PROD 환경
주문 수 : 300건
Kafka
partition : 4
concurrency : 2
API elapsed time : 약 12분 → 약 1초
실제 처리 시간 : 약 10~12분 → 약 3초
개선 전 API JVM

개선 후 API JVM

개선 후 Consumer JVM

자원 사용 비교
기존 API 서버는 요청 처리 중 JVM 자원 (CPU 및 메모리) 급증
개선 후 API 서버는 가볍게 메시지만 전송, Kafka Consumer에서 분산 처리
API 서버 안정성 향상, POD 장애 가능성 제거
Consumer의 자원 사용량은 일부 증가하였지만 Kafka 기능 특성상 Lazy하게 처리하기 때문에 수용가능한 수준임을 확인
5. 느낀 점
이번 개선은 단순한 성능 향상이 아니라, 비즈니스 흐름을 시스템 구조 측면에서 재설계한 경험이었습니다.
새로운 기능을 만드는 것보다, 기존 로직을 유지하면서 구조 개선하는 것이 훨씬 어렵고 에너지 소모가 크다
구조적으로 개선하지 않으면 일시적인 성능 개선은 한계가 있다는 점을 체감
Kafka 기반 아키텍처 설계와 병렬 처리 구조에 대한 확신과 이해를 얻는 계기가 되었다
출고지시 기능의 개선함으로써 사용자 경험에도 긍적적 영향을 미쳤을 것으로 생각됩니다.