

Redis Cluster 세팅 및 Application 구현해보기
1. Redis Cluster란 무엇인가?
Redis Cluster는 Redis의 분산 구현으로, 여러 노드에 데이터를 샤딩(분산 저장)하는 고가용성 솔루션입니다. 일반 Redis와 달리 데이터가 여러 노드에 자동으로 분산되어 저장되며, 이를 통해 다음과 같은 이점을 제공합니다:
데이터 샤딩: 데이터를 여러 노드에 자동으로 분산 저장
고가용성: 일부 노드에 장애가 발생해도 작업 계속 가능
수평적 확장성: 부하 증가 시 노드를 추가하여 처리 능력 향상
Redis Cluster는 특히 단일 Redis 인스턴스의 메모리 한계를 초과하는 대규모 데이터셋이나 높은 처리량이 필요한 환경에서 유용합니다.
2. Redis Cluster 구성 과정
Redis Cluster를 구성하는 일반적인 방법은 Docker Compose를 사용하는 것입니다. 다음은 3개의 마스터 노드와 3개의 슬레이브 노드로 구성된 Redis Cluster를 설정하는 방법입니다.
2.1. Docker Compose 구성
version: '3.8'
services:
redis-node-1:
image: redis:latest
container_name: redis-node-1
ports:
- "6379:6379"
volumes:
- ./redis-node-1.conf:/usr/local/etc/redis/redis.conf
- redis-node-1-data:/data
command: redis-server /usr/local/etc/redis/redis.conf
networks:
- redis-net
redis-node-2:
image: redis:latest
container_name: redis-node-2
ports:
- "6380:6380"
volumes:
- ./redis-node-2.conf:/usr/local/etc/redis/redis.conf
- redis-node-2-data:/data
command: redis-server /usr/local/etc/redis/redis.conf
networks:
- redis-net
# 나머지 노드 (3-6) 구성...
redis-cluster-init:
image: redis:latest
container_name: redis-cluster-init
command: >
bash -c "
sleep 20 &&
echo 'Creating Redis Cluster...' &&
(echo 'yes' | redis-cli -a redisauth --cluster create redis-node-1:6379 redis-node-2:6380 redis-node-3:6381 --cluster-replicas 0) &&
echo 'Adding slave nodes...' &&
sleep 5 &&
redis-cli -a redisauth --cluster add-node redis-node-4:6382 redis-node-1:6379 --cluster-slave &&
sleep 5 &&
redis-cli -a redisauth --cluster add-node redis-node-5:6383 redis-node-2:6380 --cluster-slave &&
sleep 5 &&
redis-cli -a redisauth --cluster add-node redis-node-6:6384 redis-node-3:6381 --cluster-slave &&
echo 'Redis Cluster setup completed successfully!'
"
networks:
- redis-net
depends_on:
- redis-node-1
- redis-node-2
- redis-node-3
- redis-node-4
- redis-node-5
- redis-node-6
networks:
redis-net:
driver: bridge
volumes:
redis-node-1-data:
redis-node-2-data:
redis-node-3-data:
redis-node-4-data:
redis-node-5-data:
redis-node-6-data:
2.2. Redis 노드 구성 파일
각 Redis 노드는 자체 설정 파일이 필요합니다. 다음은 마스터 노드의 구성 예시입니다:
port 6379
dir /data
bind 0.0.0.0
protected-mode no
appendonly yes
requirepass redisauth
masterauth redisauth
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
주요 설정:
cluster-enabled yes: 클러스터 모드 활성화requirepass및masterauth: 인증 설정cluster-node-timeout: 노드 장애 감지 시간
2.3. 클러스터 초기화
클러스터 초기화는 redis-cluster-init 서비스에서 이루어집니다. 이 서비스는:
마스터 노드(1-3)를 사용하여 클러스터 생성
마스터 1 - 슬레이브 4
마스터 2 - 슬레이브 5
마스터 3 - 슬레이브 6
각 마스터 노드에 슬레이브 노드 연결
클러스터 구성 완료
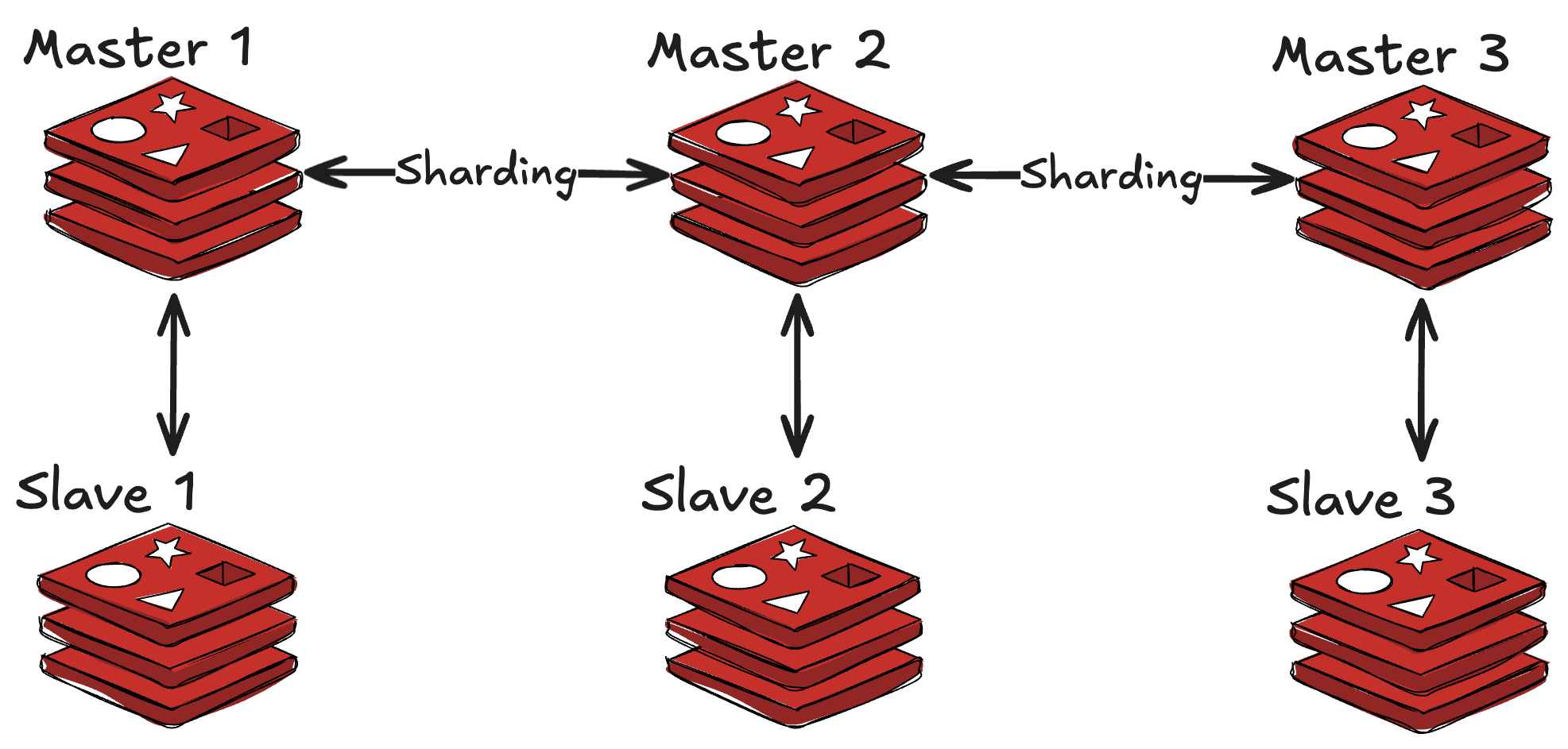
Redis Cluster 아키텍처

지금까지한 redis-cluster를 실행하면 다음과 같은 형태로 시스템이 구성될 것될 것입니다.
3개의 마스터 노드, 3개의 슬레이브 노드를 가지고 있으며 마스터 노드는 각 마스터 노드끼리 슬롯을 3등분하여서 사딩하고 있습니다.
만약 이런 상황에서 1개의 마스터 노드를 추가적으로 할당하면 어떻게 될까요?
그러면 다음과 같은 일련의 과정을 거치게 될 것 입니다.
새롭게 추가된 마스터 노드에 슬롯 할당
새롭게 할당된 슬롯에 대해서 다른 노드들로 부터 데이터 복제
slave 노드 할당
이 내용에 대해서는 별도로 내용을 다루도록 하겠습니다.
3. Redis Cluster 애플리케이션 구성
Spring Boot에서 Redis Cluster를 연동하는 방법을 알아보겠습니다.
3.1. 프로젝트 의존성 설정 (build.gradle.kts)
plugins {
kotlin("jvm") version "1.9.25"
kotlin("plugin.spring") version "1.9.25"
id("org.springframework.boot") version "3.4.5"
id("io.spring.dependency-management") version "1.1.7"
}
dependencies {
implementation("org.springframework.boot:spring-boot-starter-data-redis")
implementation("org.springframework.boot:spring-boot-starter-web")
implementation("com.fasterxml.jackson.module:jackson-module-kotlin")
implementation("org.jetbrains.kotlin:kotlin-reflect")
testImplementation("org.springframework.boot:spring-boot-starter-test")
}
3.2. 애플리케이션 설정 (application.yml)
spring:
application:
name: redis-cluster
redis:
cluster:
nodes: redis-node-1:6379,redis-node-2:6380,redis-node-3:6381,redis-node-4:6382,redis-node-5:6383,redis-node-6:6384
password: redisauth
timeout: 60000
server:
port: 8080
3.3. Redis 연결 설정 (RedisConfig.kt)
@Configuration
class RedisConfig {
@Value("\${spring.redis.cluster.nodes}")
private lateinit var clusterNodes: List<String>
@Value("\${spring.redis.password}")
private lateinit var password: String
@Bean
fun redisConnectionFactory(): RedisConnectionFactory {
val clusterConfig = RedisClusterConfiguration(clusterNodes)
clusterConfig.setPassword(password)
return LettuceConnectionFactory(clusterConfig)
}
@Bean
fun redisTemplate(): RedisTemplate<String, Any> {
val template = RedisTemplate<String, Any>()
template.connectionFactory = redisConnectionFactory()
template.keySerializer = StringRedisSerializer()
template.valueSerializer = StringRedisSerializer()
return template
}
}
3.4. Redis 컨트롤러 (RedisController.kt)
@RestController
@RequestMapping("/api/redis")
class RedisController(private val redisTemplate: RedisTemplate<String, Any>) {
@GetMapping("/get/{key}")
fun getValue(@PathVariable key: String): String? {
return redisTemplate.opsForValue().get(key)?.toString()
}
@PostMapping("/set")
fun setValue(@RequestParam key: String, @RequestParam value: String): String {
redisTemplate.opsForValue().set(key, value)
return "Value set successfully"
}
@GetMapping("/test")
fun testConnection(): String {
return try {
val testKey = "test-connection"
val testValue = "Connection Successful at ${java.time.LocalDateTime.now()}"
redisTemplate.opsForValue().set(testKey, testValue)
"Redis Cluster Connection Test: SUCCESS - Value set: $testValue"
} catch (e: Exception) {
"Redis Cluster Connection Test: FAILED - ${e.message}"
}
}
}
4. Redis Sentinel과 Redis Cluster의 차이점 분석
4.1. 주요 목적
Redis Sentinel:
주 목적: 고가용성(HA) 제공
데이터 샤딩 없음(모든 데이터는 마스터에 저장)
마스터 노드 장애 시 자동 장애 복구
Redis Cluster:
주 목적: 데이터 샤딩 + 고가용성
데이터를 여러 노드에 분산하여 수평적 확장성 제공
노드 장애 시 클러스터 재구성
4.2. 아키텍처 비교
Redis Sentinel:
구성: 1 마스터 + N 슬레이브 + 센티널 모니터링 노드
모든 데이터는 마스터에 기록되고 슬레이브에 복제됨
센티널 노드는 마스터 상태를 모니터링하고 장애 발생 시 슬레이브를 마스터로 승격
Redis Cluster:
구성: 최소 3개의 마스터 노드 + 각 마스터당 슬레이브 노드
데이터는 여러 마스터 노드에 분산 저장(샤딩)
각 마스터는 자신의 슬레이브와 함께 작동
4.3. 사용 사례
Redis Sentinel:
작은 규모의 데이터셋(단일 Redis 인스턴스에 맞는 경우)
고가용성이 주요 관심사인 경우
더 단순한 아키텍처를 선호하는 경우
Redis Cluster:
대규모 데이터셋(단일 Redis 인스턴스의 메모리 한계를 초과)
높은 처리량이 필요한 경우
수평적 확장성이 필요한 경우
4.4. 구성 복잡성
Redis Sentinel:
더 간단한 설정(상대적으로)
최소 3개의 노드(1 마스터 + 2 슬레이브 + 센티널)
Redis Cluster:
더 복잡한 설정 및 관리
최소 6개의 노드(3 마스터 + 3 슬레이브)
5. 느낀점
Redis Cluster와 Spring Boot를 연동하면서 몇 가지 중요한 점을 발견했습니다:
5.1. 고가용성과 확장성의 균형
Redis Cluster는 강력한 확장성과 고가용성을 제공하지만, 그만큼 구성과 관리가 복잡합니다. 특히 작은 규모의 프로젝트에서는 Redis Sentinel이 더 단순하고 효과적일 수 있습니다. 프로젝트의 요구사항과 예상 데이터 볼륨을 고려하여 적절한 솔루션을 선택해야 합니다.
5.2. 클러스터 초기화의 중요성
Redis Cluster 설정에서 클러스터 초기화는 매우 중요한 단계입니다. 노드 간의 올바른 관계 설정, 마스터-슬레이브 연결 등이 정확히 이루어져야 클러스터가 안정적으로 작동합니다. Docker Compose를 사용하면 이 과정을 자동화할 수 있어 편리합니다.
5.3. Spring Data Redis의 추상화 레이어
Spring Data Redis는 Redis Cluster 연동을 위한 강력한 추상화 레이어를 제공합니다. RedisClusterConfiguration과 LettuceConnectionFactory를 사용하면 복잡한 클러스터 구성을 간단하게 처리할 수 있습니다. 이는 개발자가 Redis의 복잡한 내부 동작보다 비즈니스 로직에 집중할 수 있게 해줍니다.
5.4. 프로덕션 고려사항
실제 프로덕션 환경에서는 추가적인 고려사항이 필요합니다:
보안: 강력한 비밀번호 설정, 네트워크 격리
모니터링: 노드 상태, 메모리 사용량, 연결 수 등 모니터링
백업 전략: 데이터 손실 방지를 위한 정기적인 백업
성능 튜닝: 워크로드에 맞는 Redis 설정 최적화
Redis Cluster는 대규모 데이터셋과 높은 처리량이 필요한 시스템에 적합한 강력한 솔루션입니다. Spring Boot와의 통합을 통해 확장 가능하고 고가용성을 갖춘 캐싱 및 데이터 저장 솔루션을 구축할 수 있습니다.
마무리
Redis Cluster와 Redis Sentinel은 각각 다른 목적과 강점을 가진 Redis의 고가용성 솔루션입니다. 프로젝트의 규모, 데이터 볼륨, 확장성 요구사항 등을 고려하여 적절한 솔루션을 선택하는 것이 중요합니다. Spring Boot와의 통합을 통해 이러한 솔루션을 쉽게 구현하고 관리할 수 있어, 견고하고 확장 가능한 애플리케이션을 개발할 수 있습니다.